
What Quantum Chemistry Teaches Us About Building Research Agents
With El Agente Quntur, we demonstrate that research agents should be built around modular, field-specific abstractions rather than collections of task-specific workflows.

Computational chemistry research is structured, but not linear: it requires moving between scientific questions, molecular models, method choices, software syntax, failed jobs, diagnostic checks, literature context, and chemical interpretation, with each step potentially changing what the next step should be. Quntur was designed around the idea that a research agent should preserve this adaptive structure rather than compress it into a fixed workflow.
One may think that we can build scientific agents by starting with a successful workflow and then expand from there. However, workflow accumulation alone quickly becomes difficult to scale and brittle if the goal is to support research. The agent may know many familiar path yet still struggle when a new problem requires recombining parts of those capabilities. We built El Agente Quntur on top of El Agente Q’s cognitive architecture and designed it following a different premise: the scalable unit or module of a scientific agent should not be an individual workflow, but the scientific domain. These domains, or abstractions, recur across software packages: choosing a method and basis set, deciding which approximations are acceptable, diagnosing convergence failures, reasoning about three-dimensional molecular structure, checking results against theory or literature, etc. Many quantum chemistry software packages provide different ways to materialize these abstractions, but they do not define the capabilities themselves. Adding a new module should therefore not correspond to adding a new software capability, skill, or workflow, but to expanding what the agent can reason about while solving a problem.
El Agente Quntur architecture
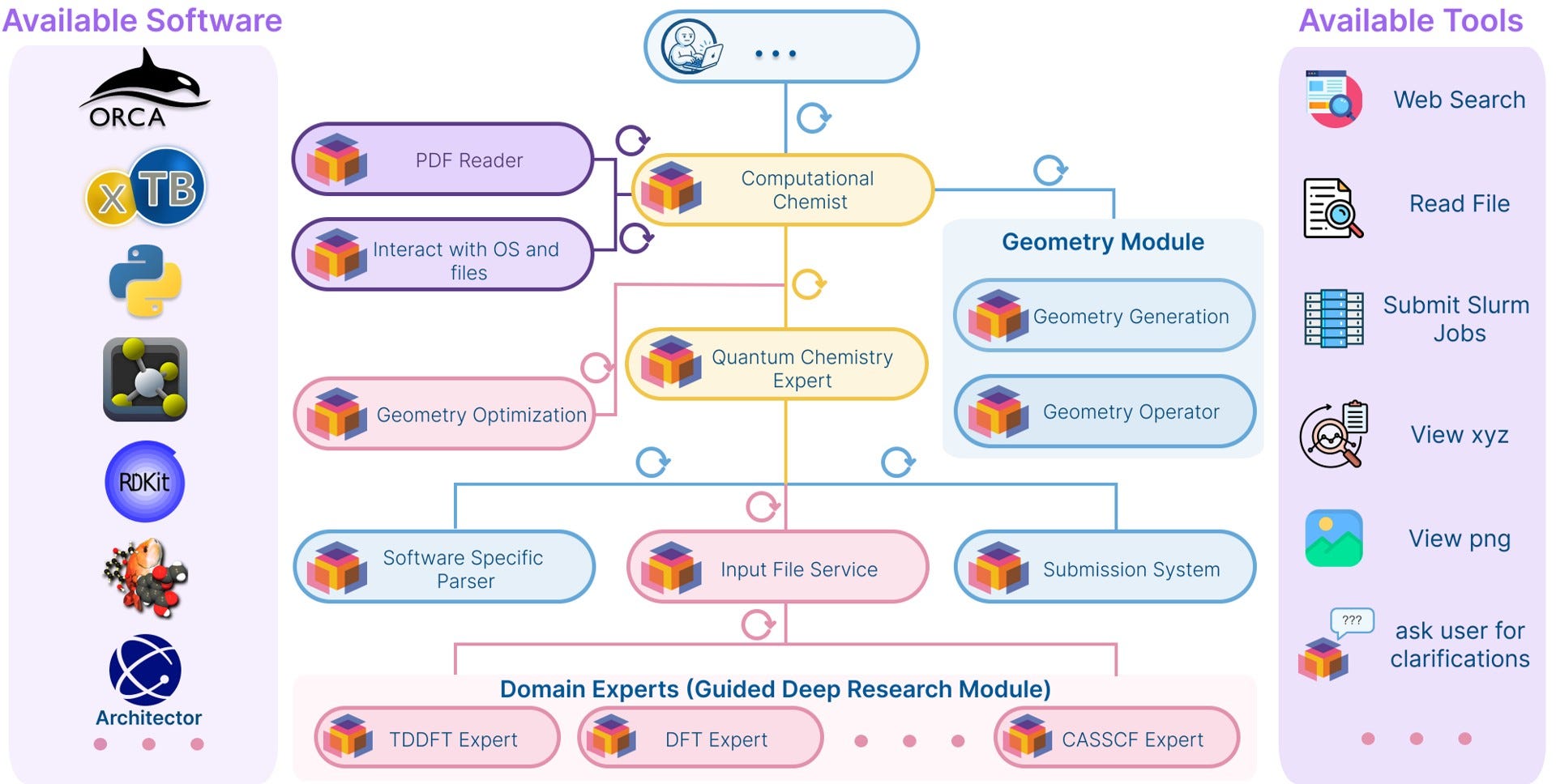
At the top level, Quntur has a computational chemist agent that formulates the problem, builds a plan, and delegates work to more specialized agents. Downstream modules handle geometry generation, interaction with files and operating-system tools, software-specific parsing, job submission, and input-file construction. The input-file service is especially important because it sits at the boundary between chemical reasoning and software realization. It must decide not only what calculation should be done, but how that calculation should be expressed in a particular quantum-chemistry backend.
That is where guided deep research comes into play. Instead of encoding every ORCA keyword, PySCF option, spectroscopy block, or excited-state recipe as a permanent hand-written rule, Quntur can search software documentation and research scientific literature at execution time. Domain specialists investigate the relevant theory and syntax, while an orchestrating agent decides which specialists are needed and how their findings should be assembled. This matters because input-file synthesis in quantum chemistry couples three difficult tasks at once: selecting a physically meaningful method, choosing the observable or analysis that matches the scientific question, and mapping those choices onto software-specific commands. A scientifically sensible choice encoded incorrectly will fail. A syntactically valid input that encodes the wrong conceptual assumption may run, but produce a meaningless result.
The same design logic appears in Quntur’s tools, although much more restrictively. For example, rather than relying solely on parser wrappers for every possible output variant, it can index sections, inspect targeted line ranges, run shell and Python commands, view molecular structures, and analyze generated images using bash scripts. Quntur still provides tool wrappers for delicate programs like orca_plot where documentation is not transparent and mistakes are costly. Yet, in general, letting the subagents build their own tools on the fly has become a promising direction as coding abilities of frontier models continue to improve their coding abilities.
The benchmark
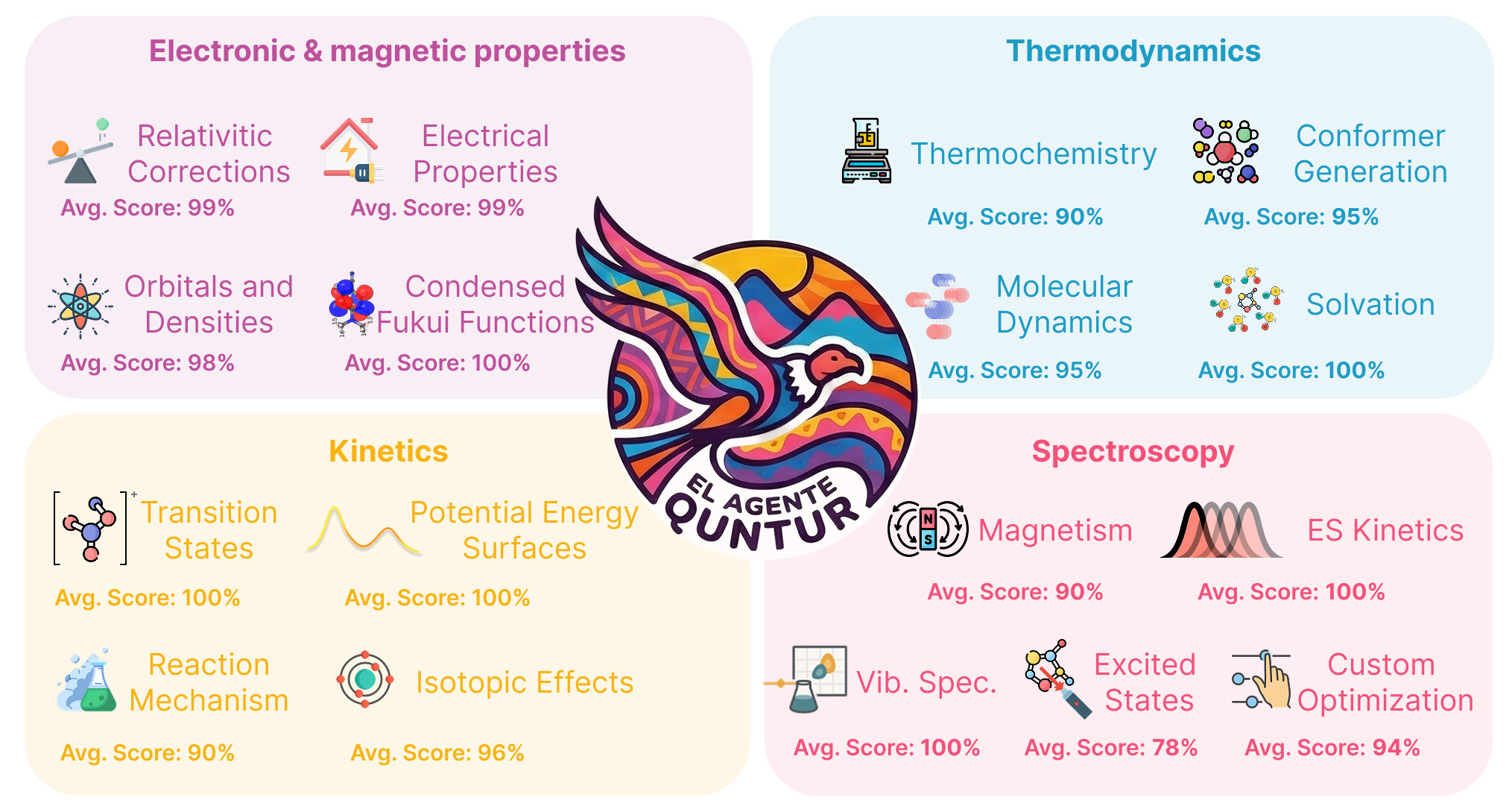
Benchmarking scientific agents is a challenge in its own. For many quantum-chemistry tasks, an agent can perform the mechanical part of the job: generate an input, run the software, parse the output, and report a number. But research-level performance depends on more than execution. It depends on whether the agent chose a sensible method, understood the limits of the approximation, recognized when the results did not answer the intended question, and interpreted the output in a chemically meaningful way.
This exposes one of the central challenges for AI agents in chemistry: there is not yet a standardized benchmark that fully captures scientific reasoning, methodological judgment, and interpretation. In this paper, we do not attempt to solve such an important problem. Yet, we design a benchmark set to evaluate Quntur on tasks spanning problems on electronic and magnetic properties, thermodynamics, kinetics, and spectroscopy, using repeated runs and expert rubrics to assess not only whether the task was completed but also whether the reasoning behind the result was scientifically defensible. Figure 2 must therefore be understood alongside the questions and rubrics we designed, which are available in the manuscript’s Supplementary Information. For example, the low score obtained in excited state calculations may give the impression that the agent generally performs poorly on this task, but careful examination of the rubrics reveals that the low score emerges solely from an inconsistent choice of DFT functional between geometry optimization and excited state single point calculations, a choice that our expert reviewer flagged as a mistake made by Quntur during the planning phase.
El Agente Quntur as research collaborator
A simple example is the DMABN excited-state case study. DMABN, or 4-(dimethylamino)benzonitrile, is a donor–acceptor molecule whose photophysics depends on the distinction between locally excited, charge-transfer, and twisted intramolecular charge-transfer states. We asked Quntur to compute the two lowest singlet excited states using TDDFT, visualize natural transition orbitals, and compare the S1 transition at the ground-state and relaxed excited-state geometries. This is not a one-command problem. It requires a plan for ground- and excited-state geometries, as well as many other components, such as TDDFT calculations, Natural Transition Orbitals (NTOs) images generation, visualization, and interpretation of orbital character.
In this example, Quntur produced a multi-step plan, generated and inspected natural transition orbital images, and concluded that S2 is the bright predominantly π→π* state, while S1 is darker and has partial charge-transfer character. It also recognized an important caveat: although S1 was assigned as a charge-transfer state, its optimized geometry remained relatively planar rather than adopting the twisted intramolecular charge-transfer geometry reported in previous works. The agent hypothesized that this discrepancy could arise from the neglect of solvent effects, which may alter the stabilization of charge-transfer geometries. This is the kind of step that distinguishes a research collaborator from a job runner. The agent not only produced files; it interpreted the result in relation to the conditions of the calculation. Now, human researchers can interact with Quntur to review computational steps, perform further quantum chemistry analysis, or continue the analysis by running additional calculations using different solvents and solvation models.
Limitations
The limitations are just as important as the successes.
At this point, we believe Quntur is not a replacement for computational chemists and is not yet a fully autonomous, end-to-end scientific system. Human oversight remains crucial to account to address missing capabilities, problem framing, methodological judgment, validation, and decision-making in cases where several scientifically defensible paths exist, or to counteract vagueness in the prompt. Some concrete specific bottlenecks and limitations that we’ve identified are
Language models have limited planning capabilities, as their ability to foresee challenges is limited. Methodology issues that are easily predicted by humans are only detected by agents during execution;
Three-dimensional geometric reasoning remains difficult, especially for generating transition-state guesses and other exotic geometries;
Poor scientific judgement. AI agents often misinterpret coincidental trends as universal rules.
These issues are not minor details and whether they will eventually vanish as language models improve is up for debate.
Roadmap
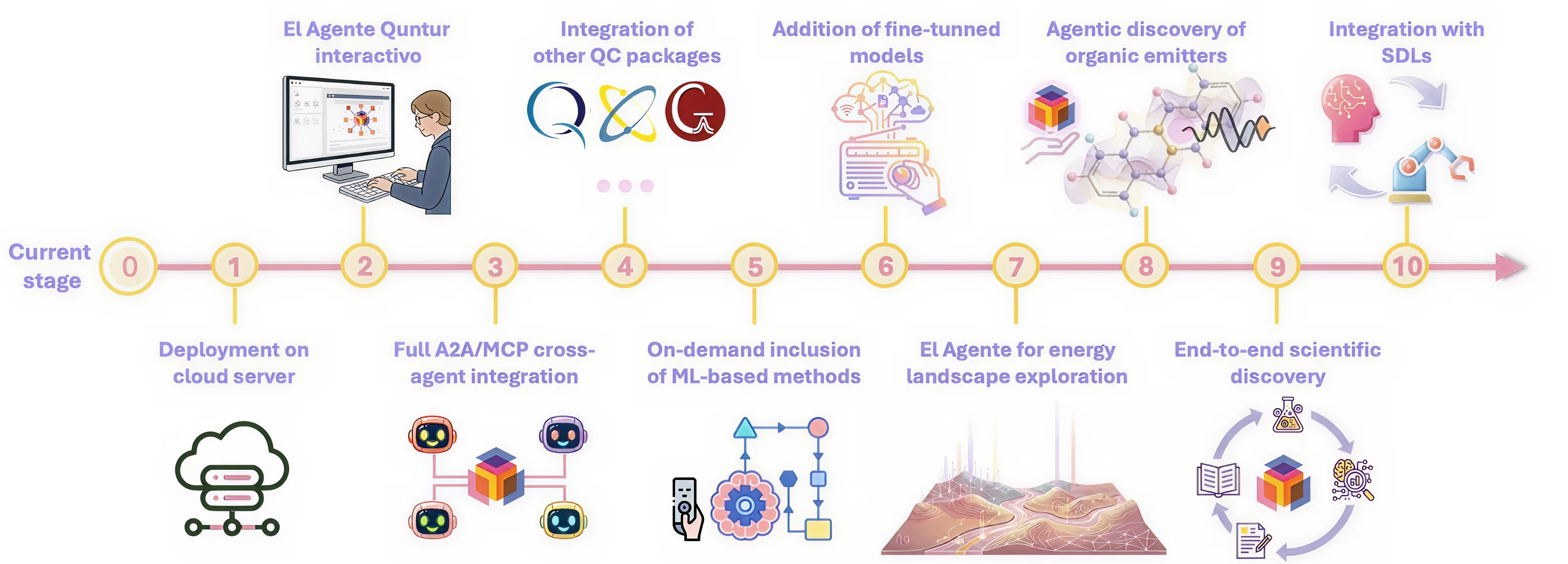
We designed Quntur as a tool for quantum chemistry research problems, and our roadmap is oriented toward research applications. We believe that, through modular assembly of Quntur and other agents, it will be possible to tackle problems such as energy landscape exploration, drug discovery, discovery of organic materials, and reaction mechanism analysis, with eventual integration with self-driving laboratories.
Bottom line
One cannot scale scientific agents by accumulating workflows. That strategy may produce impressive demonstrations by overfitting the system to benchmark, but it will fail miserably in research scenarios, eventually exposing the brittleness of traditional automation. El Agente Quntur offers a more flexible alternative. We treat scientific agency as an architectural problem: decompose research into reusable capabilities, connect those capabilities across software domains, let agents research and adapt at execution time, and keep humans in the loop where judgment matters. In quantum chemistry, this distinction may separate an agent that simply executes calculations from one that actively supports reasoning throught them.